 Europe PMC Tech Blog
Europe PMC Tech BlogIntegrating Literature and Data
Data is at the heart of research. Scientific papers describe how data has been obtained, analysed, and what conclusions have been drawn. But it is the data that comprises the essential evidence, which confirms or disproves the original hypothesis. In the life sciences it is essential to look at scientific literature in the context of other publications, the data it builds on and other data linked to the publication. At Europe PMC we have developed a number of features to support data discovery and reuse.
As one of the ELIXIR Core Resources, Europe PMC benefits from excellent links to essential research data hubs located at EMBL-EBI. This helps us interweave publications and data, enriching the graph of research objects, and help researchers discover linked and related data.
The literature-data links come in different forms and shapes. An article might be citing a DOI for a dataset in a repository, or describe a protein structure cited as an accession number for PDBe database. An publication itself might be cited by a database, such as Flybase or even a Wikipedia article. Europe PMC obtains such literature-data links in three ways: they might be provided directly by databases at the EBI; submitted by providers participating in Europe PMC external links program; or picked up directly by our text-mining pipeline that extracts data mentions, such as accession numbers, from research publications. The three link types largely share the same characteristics, but used to be scattered through the Europe PMC website. They would show up in different locations and were obtained through different web service methods in different formats, even though they all link external content, mostly data, to the publication.
Based on their commonalities and use, it made sense for us to start consolidating our datalinks in the Europe PMC API, as well as in their presentation through the Europe PMC website. To adhere to community standards and allow exchange of data with other providers, we have turned to the Scholix format for scholarly link exchange, which we have helped to shape and have subsequently used to represent datalinks in Europe PMC web services.
Collaborating with Scholix
Scholix, or Scholarly link exchange, is an initiative is to establish a multi-hub infrastructure to harmonize and enable the exchange of data-literature links between several natural hubs, such as DataCite, CrossRef, or OpenAIRE, in scholarly communities. The centerpiece of the Scholix landscape is the format that is used to facilitate link exchange between the hubs and other interested parties. Data links in Scholix format are presented as an “information package”. The package contains information about the two linked objects (e.g. a publication and a dataset), as well as link metadata: date, provider, copyrights, etc.
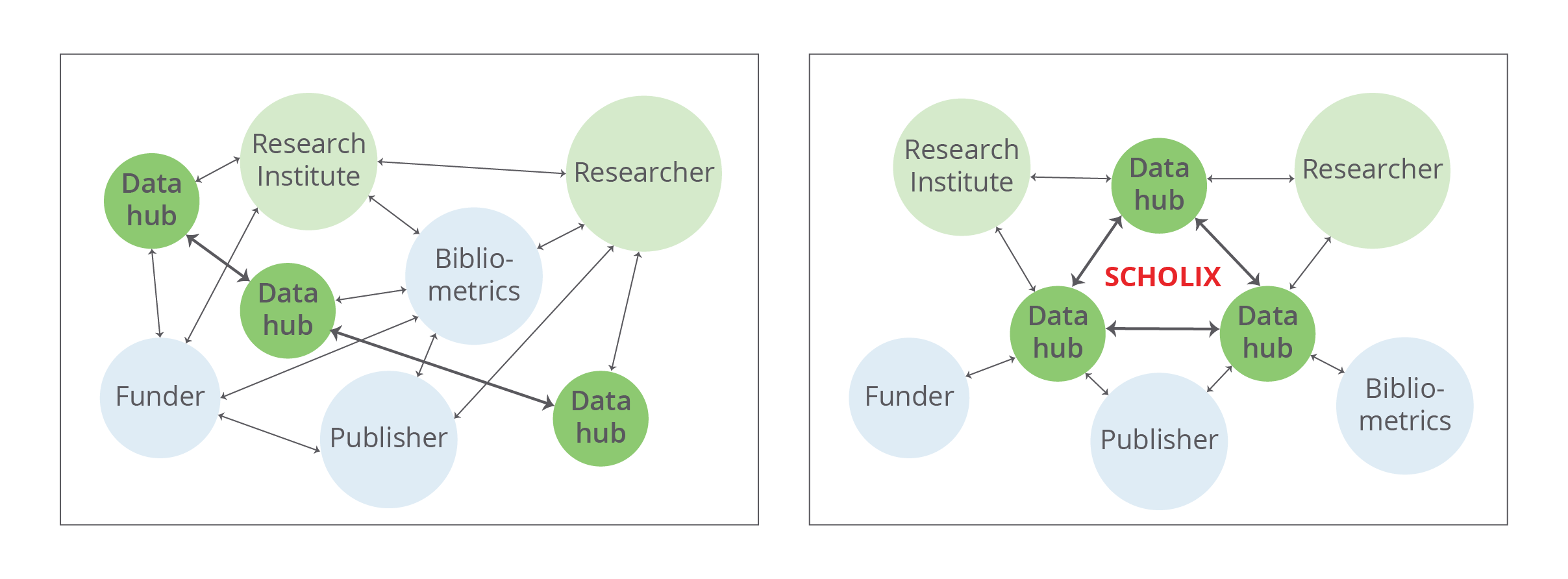 Figure 1: Scholix hub architecture
Figure 1: Scholix hub architecture
Europe PMC is a part of the Research Data Alliance World Data System (RDA/WDS) Working Group on Scholarly Link Exchange that has pioneered the Scholix format and the multi hub approach. To consolidate internal data link formats and simplify exchange with external partners we have built the Europe PMC API method for data links around the Scholix format.
Implementing Scholix for Europe PMC
When implementing Scholix format for literature-data links in Europe PMC we had to take into account specific requirements imposed by Europe PMC front end. The Scholix information package provides a core set of metadata, which we have supplemented with custom elements. As mentioned before, data links in Europe PMC come in through three main routes and have some unique specifications. For example, the information package for text-mined accessions in addition to the standard Scholix metadata will include the number of occurrences in text, while a link submitted via External links program might contain an image - e.g. metrics information provided by Altmetrics. In order to preserve this additional information we have embedded Scholix link information package into a hierarchy of categories. One category corresponds to a single resource which hosts the data linked to a publication. For each category (e.g. Uniprot, Wikipedia, Altmetrics) there might be multiple links within the article. Those links are further categorised as sections, depending on the method, which we used to obtain it. Consequently, there are three available sections: Text-mined links (Biological Entities and Accessions of such, discovered through our text-mining pipeline) Database cross-references (Links to EBI resources submitted directly to Europe PMC) External links (Links submitted through the Europe PMC external links program. This is a mixed set, which includes database records, as well as links to lay summaries, press releases and open peer reviews)
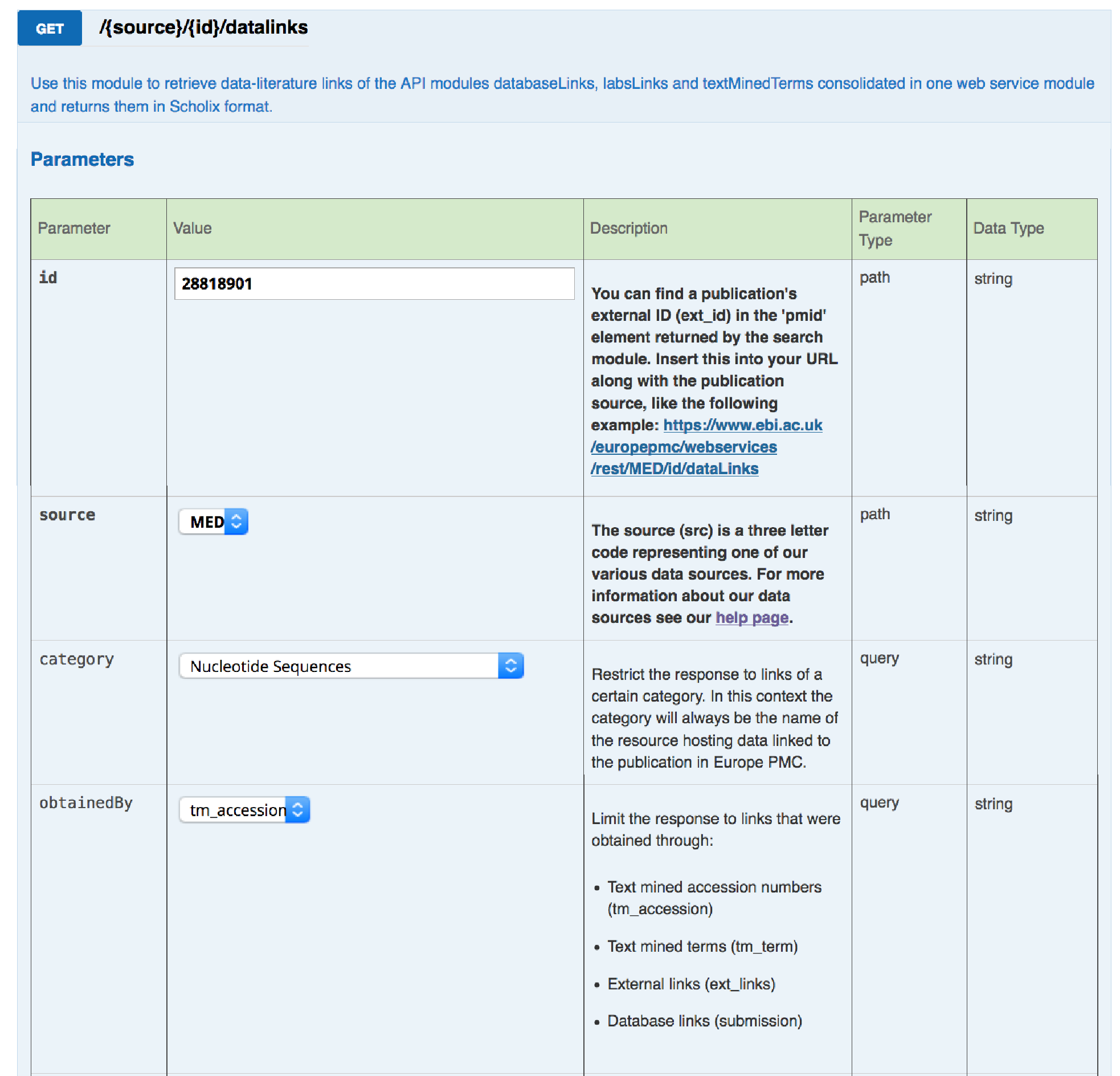 Figure 2: Interactive swagger documentation of the datalinks web service method
Figure 2: Interactive swagger documentation of the datalinks web service method
The categories and sections are reflected in Europe PMC Swagger-powered RESTful API documentation. If you want to try it out, query https://www.ebi.ac.uk/europepmc/webservices/rest/MED/28818901/datalinks?format=json to retrieve all links associated with the publication PMID:28818901 in JSON format.
For Europe PMC API users, or those who are planning to give the Europe PMC API a go, we recommend signing up for Europe PMC developer forum. We are keeping subscribers up to speed with changes and help out if there are any questions regarding Europe PMC APIs. You may also find like-minded peers using the datalinks API method already.
For the front end users this means having all data links conveniently combined in a single place on the article page - the Data tab. It contains links to supplemental files hosted by the BioStudies database, as well as related data, or data cited in the article.
 Figure 3: The new Europe PMC data tab
Figure 3: The new Europe PMC data tab
To wrap up
Overall the new data links module not only powered a new user-facing feature (the Data tab), but it also consolidated three existing API methods related to data-literature links into one, simplifying and enabling major front end developments in the future. Furthermore, using the Scholix format helps make literature-data links available and accessible to data link hubs like Datacite, CrossRef, and OpenAIRE, as well as to individual data scientists using Europe PMC.